CEO
WaveOne

First and foremost, I am a technology enthusiast. We live in exciting times! Times of great scientific progress and exponential growth. The past five years are marked by unprecedented advances in Artificial Intelligence, Nanotechnology and Genetic Engineering. Self-driving cars, intelligent assistants and new sources of energy are just around the corner. Nobody knows where we are headed but we sure are going fast and accelerating! My dream is to be in the very center of this journey.
I am espeically fascinated by Artificial Intelligence, Machine Learning and specifically Computer Vision. My first computer vision project was a face detector I developed at Adobe together with my colleague Jon Brandt. It was based on what we called the Soft Cascade, a novel at the time cascade architecture that allows for building detectors that have good balance between speed and accuracy. As far as I know our detector, introduced in 2005 in Photoshop Elements 4.0, was the first consumer product to feature face detection.
PhD in Computer Vision was a natural next step for me, but I could not afford to leave industry to pursue a Ph.D. Luckily, my employer was extremely generous and allowed me to do my PhD while still being on payroll at David Salesin's Creative Technologies Lab at Adobe. I did my PhD at UC Berkeley under the supervision of Prof. Jitendra Malik from 2007-2011. My research interest was in part-based models, and I developed, together with my advisor, a part-based method called Poselets. The power of poselets was the ability to untangle pose from appearance and model them separately, which allowed us to use them for many high-level computer vision tasks. My detector for people in images was the most accurate one in standard computer vision datasets in the period 2010-2012.
Around that time it was becoming obvious that further progress in computer vision is bound by data availability, and Facebook has by far the largest collection of consumer photos. In early 2012 I joined Facebook with the goal to apply computer vision analysis on the hundreds of billions of photos on the site. I am the first person hired at Facebook to pursue computer vision and I am a founding member of Facebook AI Research. Together with my then-intern Manohar Paluri, we developed the object recognition engine that Facebook uses to detect thousands of objects, scenes, activities and places of interest. It is based on Convolutional Neural Networks and runs on every photo on Facebook and Instagram and every second of every video. It has been run more than half a trillion times and is key in spam detection, pornographic content filtering, visual search, feed ranking and many other areas. I was initially the project lead and then became the manager of the computer vision group at Facebook's Applied Machine Learning division. I found the skills I learned as a manager in the high paced and unstructured Facebook environment extremely valuable.
I co-founded and was the CEO of WaveOne, Inc., a technology company focusing on reinventing video compression with deep learning. Nearly 80% of the internet is dominated by video and the existing codecs use no machine learning whatsoever. Leveraging generative AI we were able to outperform the standards by a wide margin, as shown for I-frames here. We engaged with large companies and the US Government. We sold the company to Apple in 2023.
Software Engineering is also one of my professional passions. In many ways software engineering resembles art because in both one strives for simplicity and perfection. I started writing code in middle school, around 1987, for Apple II, initially with a pen in a notebook because I didn't have a computer back then. My first large-scale software project (20K+ lines of code) was a module, called The Flattener, that converts documents that have semi-opaque vector elements to a form that is fully opaque, using both geometry and color transformations. Adobe uses this module every time one prints or exports a document from Acrobat, Illustrator, InDesign and they also license it to other companies like Kodak. The software engineering project I am most proud of was the Generic Image Library (GIL) I wrote together at Adobe with my colleague Hailin Jin. This library allows one to decompose algothims from image layouts and write the algorithm once and have it work with all kinds of images without loss of performance. GIL is now part of the Boost libraries and is used by many companies and universities. It was a great honor for me to be invited by Prof. Bjarne Stroustrup, the creator of C++, to give a talk about GIL at Texas A&M University.
I love practicing martial arts, playing tennis, table-tennis, hiking, biking, and travelling around the world. I have visited 30+ countries on four continents. I love tasting all kinds of local cuisines although my options are limited by the fact that I am a vegetarian.
WaveOne
UC Berkeley, Computer Science Department
Facebook, Applied Machine Learning
Facebook, Facebook AI Research
Adobe, Adobe Research
Ph.D. in Computer Science
University of California at Berkeley
Master of Arts
in Computer Science
Brown University
Bachelor of Science
in Computer Science
Brown University
Here I describe the more significant software engineering projects and features I have developed at Adobe and Facebook. I was the project lead in each of these projects

When I joined Facebook in February 2012 I was the first person at the company hired to do computer vision. My first task was evaluating the Face.com technology and providing technical advice on the acquisition as well as integrating the technology into Facebook. After that I focused on object and scene recognition. Together with my then-intern Manohar Paluri, we developed the computer vision engine that Facebook uses to analyze photos and videos. It was incredibly exciting to deploy an engine and have it run on three hundred million photos per day! The original engine was based on traditional computer vision features and was able to tell basic properties, like whether the photo is a closeup, indoors or outdoors, or in nature. Over the next two years we released nine versions of the engine, significantly improving it in each release. The latest version is able to recognize more than a thousand types of objects, scenes, activities and places of interest using convolutional neural networks with multiple loss functions. At peak time it handles more than 10000 calls per second and is run on every photo and every second of every video on Facebook and Instagram. It has already been called more than half a trillion times! Our engine is key for spam detection, pornographic content filtering, visual search, feed ranking, ad targeting, and many other areas. I was first the project lead and then became the manager of the group responsible for everything from the research to the development and deployment of the engine. I developed a large part of the training code as well as a highly optimized feedforward path used in production.

This was my first research project. Since Computer Vision was a new area for me, I started by reading papers and textbooks. My first experiment was a human ear detector using a neural network on the Haar wavelets of an image. It worked fairly well, but evaluating the neural network at every location and scale was too slow. I then spent some time thinking about evaluating the neural network incrementally, simultaneously at every place, and focusing the computations on the most promising areas. Although the total detection time deteriorated, this approach resulted in discovering most ears almost instantaneously and allowed for a nice tradeoff between detection rate and speed. I then generalized my idea to incrementally evaluate any learning machine (which I called the Soft Cascade).
A colleague of mine, Jonathan Brandt, was investigating the (at the time) state-of-the-art Viola-Jones face detector, which had very good performance and accuracy. I decided to apply the Soft Cascade on the VJ detector, and, to my delight, the resulting system was both faster and more accurate. It also has numerous advantages - it considers some information that the "hard cascade" throws away. The detector is less "brittle" and generalizes better, the speed/accuracy tradeoff is not hard-coded during training, but could be specified afterwards, and the new framework allows for augmenting the operational domain of an existing detector. For example, we could improve an existing detector to handle, say, wider out-of-plane rotation. My colleague observed that the ability of the Soft Cascade to be quickly calibrated for a specific point in the speed/accuracy space allows us to explore the operational domain of the detector not just along the detection rate and false positive rate, but also along the speed dimension. As far as I know, our CVPR paper was the first to describe the ROC surface of an object detector.
My face detector was first deployed in the face tagging feature of Photoshop Elements 4, and has received positive reviews. It wouldn't have happened without the help of Claire Schendel, a Photoshop engineer who integrated the feature into the product. As far as I know, Photoshop Elements 4, in 2005, was the first application to use face detection in a consumer product. Face detection started appearing in cameras shortly after that.
In 2007 I started developing a system that uses face detection combined with face recognition, leveraging context, such as the fact that the same people on the same day tend to wear the same clothes. This was a research project for my class at UC Berkeley which formed the basis of the People Recognition feature in Photoshop Elements 8. My Adobe colleague Alex Parenteau and I developed the core engine, using an external face recognizer and we collaborated with the Elements engineering team. The big engineering challenge we addressed was scalability - the ability to extend the technology to very large albums with limited memory.

While at Adobe I was fortunate to have Alex Stepanov, the main guy behind STL, as my colleague. He led a class on Generic Programming, which was an inspiration to all of us. Generic Programming is exciting because it allows for abstraction with no loss in performance. I have been collaborating with Prof. Jarvi from Texas A&M on a method for applying generic programming to create C++ code that is generic, efficient and run-time flexible, without incurring unnecessary code bloat. Here is our LCSD paper and my presentation slides. Our approach achieves the specified goals, but has other disadvantages, namely type safety.
One excellent application for generic programming is to abstract away the image representation and allow us to write generic image processing algorithms that work efficiently with images of any color space, channel ordering, channel depth, and pixel representation. This is the goal of my Generic Image Library - a C++ library I have created together with my former colleague Hailin Jin. GIL is an open-source library now part of the popular Boost libraries and it is used by dozens of institutions. Here is a video tutorial I prepared to give an overview of GIL.
It was a great honor for me to receive an invitation by Prof. Bjarne Stroustrup, the creator of C++, to give a talk about GIL at his institution.
Have you ever applied for a mortgage? After going through the experience of filling a billion forms, with the same information over an over again, I decided I have had enough and started thinking about ways of simplifying the form filling experience. I created a probabilistic framework that can suggest suitable defaults for form entries. It observes your entry patterns, learns from experience and is able to extrapolate the results to previously unseen forms. When it is fairly confident with the result, it can populate the field once you tab into it. It is now used by Adobe Acrobat to streamline the form filling process. I think it is also in the free Acrobat Reader. (You need to enable it from the preferences menu). Thanks to Alex Mohr, an Acrobat engineer, for integrating my engine into the product.

Vector graphics applications like Adobe Illustrator have been used to create some amazing art. But we have only scratched the surface of what computers can do. By building some intelligence into the tools, we could enable a new generation of art that would be too time consuming to generate and edit by hand. This idea inspired me to create the Symbolism tools - a suite of tools in Illustrator that allow for scattering, moving, "combing", coloring and applying styles to a collection of graphical symbols. These tools could be used for a variety of objects, like hair, organic shapes, pen-and-ink style of shading. I am using a particle system to guide the behavior of the tools. My manager Martin Newell gave me some insightful ideas for the underlying technology. I designed, prototyped, performance-optimized and integrated the feature into Illustrator. Here is some sample art created by these tools. The Symbolism tools have received outstanding reviews.
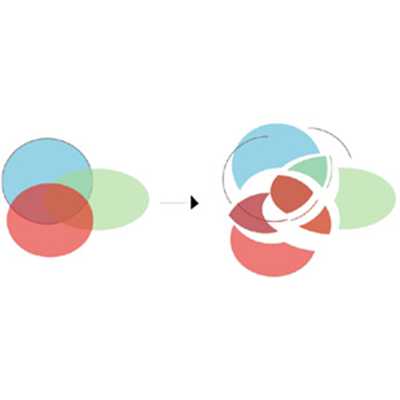
When I joined Adobe in 1998, the big company initiative was introducing transparency in the vector graphics products. Transparency can be used to represent a dazzling range of effects, see-through objects, lens effects, soft clips, drop shadows... However, the biggest technical challenge was the ability to print vector graphics with transparent elements. Adobe PostScript, the universal language of printers, does not support transparency. There were two options for printing - rasterizing into an image and printing the image, or making an opaque illustration that looks just like a transparent one by subdividing the illustration into pieces (planar mapping), and drawing them with the appropriate color, as the illustration shows. Planar mapping results in higher quality printing as it remains resolution independent. However, it is easy to create vector art for which planar mapping results in many thousands of small pieces, some smaller than a pixel. Planar mapping in those cases would be unacceptably slow, and rasterization would be the only option. But how do we know if certain parts of the document are going to result in unacceptably many pieces, without actually computing the planar map? It is a chicken and egg problem. I invented an algorithm that quickly estimates which areas of the document need to be rasterized and which can be planar mapped. Also, planar mapping is a complex operation, but we can often get by without it, in places of the document that are not involved in transparency. But how do you know if an object is involved in transparency without checking to see if it intersects with transparent object, i.e. without computing the planar map? Another chicken and egg problem. I created an algorithm to analyze the document and determine which objects need to be included into the planar map, and then interleave the results of planar mapping to generate the final document. These are just a few examples of the problems I needed to resolve in the flattener. Other problems I had to resolve are how to preserve native type through planar mapping, how to preserve native gradients and gradient meshes, how to support spot color planes, how to avoid stitching problems when dealing with strokes, how to preserve patterns, how to deal with overprint, how to schedule the color computations to avoid doing them repeatedly, how to design the system so that it performs on a single pass (the output may be too big to keep in memory), how to make sure it is fail safe - i.e. if it runs our of memory, it should fall back, break the problem into smaller pieces and attempt to do it again...
I single-handedly designed and implemented the entire flattener module - the system that takes a vector graphics document containing transparency and outputs one that is visually equivalent but contains no transparency. (That does not include the planar mapping code, implemented by my colleague Steve Schiller). The flattener is now used by many of Adobe's vector products, including Illustrator, Acrobat and InDesign. It is used when printing and exporting to various formats, and Adobe also licenses it to other companies such as Kodak. The flattener is also ported into high-end PDF printers (RIPs). This was one of the largest and most complex projects I have ever done. It is also very widely used - not just for printing labels and posters, but also big titles like the cover of Glamour magazine.
Human perception is at the core of lossy video compression, with numerous approaches developed for perceptual quality assessment and improvement over the past two decades. In the determination of perceptual quality, different spatio-temporal regions of the video differ in their relative importance to the human viewer. However, since it is challenging to infer or even collect such fine-grained information, it is often not used during compression beyond low-level heuristics. We present a framework which facilitates research into fine-grained subjective importance in compressed videos, which we then utilize to improve the rate-distortion performance of an existing video codec (x264). The contributions of this work are threefold: (1) we introduce a web-tool which allows scalable collection of fine-grained perceptual importance, by having users interactively paint spatio-temporal maps over encoded videos; (2) we use this tool to collect a dataset with 178 videos with a total of 14443 frames of human annotated spatio-temporal importance maps over the videos; and (3) we use our curated dataset to train a lightweight machine learning model which can predict these spatio-temporal importance regions. We demonstrate via a subjective study that encoding the videos in our dataset while taking into account the importance maps leads to higher perceptual quality at the same bitrate, with the videos encoded with importance maps preferred 2.1× over the baseline videos. Similarly, we show that for the 18 videos in test set, the importance maps predicted by our model lead to higher perceptual quality videos, 2× preferred over the baseline at the same bitrate.
Human perception is at the core of lossy video compression and yet, it is challenging to collect data that is sufficiently dense to drive compression. In perceptual quality assessment, human feedback is typically collected as a single scalar quality score indicating preference of one distorted video over another. In reality, some videos may be better in some parts but not in others. We propose an approach to collecting finer-grained feedback by asking users to use an interactive tool to directly optimize for perceptual quality given a fixed bitrate. To this end, we built a novel web-tool which allows users to paint these spatio-temporal importance maps over videos. The tool allows for interactive successive refinement: we iteratively re-encode the original video according to the painted importance maps, while maintaining the same bitrate, thus allowing the user to visually see the trade-off of assigning higher importance to one spatio-temporal part of the video at the cost of others. We use this tool to collect data in-the-wild (10 videos, 17 users) and utilize the obtained importance maps in the context of x264 coding to demonstrate that the tool can indeed be used to generate videos which, at the same bitrate, look perceptually better through a subjective study - and are 1.9 times more likely to be preferred by viewers. The code for the tool and dataset can be found at https://github.com/jenyap/video-annotation-tool.git
While learned video codecs have demonstrated great promise, they have yet to achieve sufficient efficiency for practical deployment. In this work, we propose several novel ideas for learned video compression which allow for improved performance for the low-latency mode (I- and Pframes only) along with a considerable increase in computational efficiency. In this setting, for natural videos our approach compares favorably across the entire R-D curve under metrics PSNR, MS-SSIM and VMAF against all mainstream video standards (H.264, H.265, AV1) and all ML codecs. At the same time, our approach runs at least 5x faster and has fewer parameters than all ML codecs which report these figures. Our contributions include a flexible-rate framework allowing a single model to cover a large and dense range of bitrates, at a negligible increase in computation and parameter count; an efficient backbone optimized for MLbased codecs; and a novel in-loop flow prediction scheme which leverages prior information towards more efficient compression. 140% 120% 100% BD-rate relative to AV1 80% 60% 40% 20% 0%-20% 1.0 Wu et al. Habibian et al. 0.8 Liu et al. 0.6 DVC 0.4 0.2 Ours 0.0 100 200 400 Encode time (ms) 800 0.0 Wu et al. Liu et al. Habibian et al. DVC Ours 50 0.2 200 0.4 600 105 0.6 106 0.8 Decode time (ms) 107 1.0 Figure 1: BD-Rate for ML-based codecs relative to AV1 as a function of encode/decode time on HD 1080 videos [42, 14, 29, 27] (UVGdataset, PSNR metric). Our approach reduces the BD-rate by 54% relative to the current fastest MLcodecwhichreportsspeed[27], whilerunning5xfaster. We benchmark our method, which we call ELF-VC (Eff icient, Learned and Flexible Video Coding) on popular video test sets UVG and MCL-JCV under metrics PSNR, MS-SSIM and VMAF. For example, on UVG under PSNR, it reduces the BD-rate by 44% against H.264, 26% against H.265, 15% against AV1, and 35% against the current best ML codec. At the same time, on an NVIDIA Titan V GPU our approach encodes/decodes VGA at 49/91 FPS, HD 720 at 19/35 FPS, and HD 1080 at 10/18 FPS.
We present a new algorithm for video coding, learned end-to-end for the low-latency mode. In this setting, our approach outperforms all existing video codecs across nearly the entire bitrate range. To our knowledge, this is the first ML-based method to do so. We evaluate our approach on standard video compression test sets of varying resolutions, and benchmark against all mainstream commercial codecs, in the low-latency mode. On standard-definition videos, relative to our algorithm, HEVC/H.265, AVC/H.264 and VP9 typically produce codes up to 60% larger. On high-definition 1080p videos, H.265 and VP9 typically produce codes up to 20% larger, and H.264 up to 35% larger. Furthermore, our approach does not suffer from blocking artifacts and pixelation, and thus produces videos that are more visually pleasing. We propose two main contributions. The first is a novel architecture for video compression, which (1) generalizes motion estimation to perform any learned compensation beyond simple translations, (2) rather than strictly relying on previously transmitted reference frames, maintains a state of arbitrary information learned by the model, and (3) enables jointly compressing all transmitted signals (such as optical flow and residual). Secondly, we present a framework for ML-based spatial rate control — a mechanism for assigning variable bitrates across space for each frame. This is a critical component for video coding, which to our knowledge had not been developed within a machine learning setting.
We present a machine learning-based approach to lossy image compression which outperforms all existing codecs, while running in real-time. Our algorithm typically produces files 2.5 times smaller than JPEG and JPEG 2000, 2 times smaller than WebP, and 1.7 times smaller than BPG on datasets of generic images across all quality levels. At the same time, our codec is designed to be lightweight and deployable: for example, it can encode or decode the Kodak dataset in around 10ms per image on GPU. Our architecture is an autoencoder featuring pyramidal analysis, an adaptive coding module, and regularization of the expected codelength. We also supplement our approach with adversarial training specialized towards use in a compression setting: this enables us to produce visually pleasing reconstructions for very low bitrates.
This paper aims to classify and locate objects accurately and efficiently, without using bounding box annotations. It is challenging as objects in the wild could appear at arbitrary locations and in different scales. We propose a novel classification architecture ProNet based on convolutional neural networks. It uses computationally efficient neural networks to propose image regions that are likely to contain objects, and applies more powerful but slower networks on the proposed regions. The basic building block is a multi-scale fully-convolutional network which assigns object confidence scores to boxes at different locations and scales. We show that such networks can be trained effectively using image-level annotations, and can be connected into cascades or trees for efficient object classification. ProNet outperforms previous state-of-the-art on PASCAL VOC 2012 and MS COCO datasets for object classification and point-based localization.
Over the last few years deep learning methods have emerged as one of the most prominent approaches for video analysis. However, so far their most successful applications have been in the area of video classification and detection, i.e., problems involving the prediction of a single class label or a handful of output variables per video. Furthermore, while deep networks are commonly recognized as the best models to use in these domains, there is a widespread perception that in order to yield successful results they often require time-consuming architecture search, manual tweaking of parameters and computationally intensive preprocessing or post-processing methods. In this paper we challenge these views by presenting a deep 3D convolutional architecture trained end to end to perform voxel-level prediction, i.e., to output a variable at every voxel of the video. Most importantly, we show that the same exact architecture can be used to achieve competitive results on three widely different voxel-prediction tasks: video semantic segmentation, optical flow estimation, and video coloring. The three networks learned on these problems are trained from raw video without any form of preprocessing and their outputs do not require post-processing to achieve outstanding performance. Thus, they offer an efficient alternative to traditional and much more computationally expensive methods in these video domains.
Distance metric learning (DML) approaches learn a transformation to a representation space where distance is in correspondence with a predefined notion of similarity. While such models offer a number of compelling benefits, it has been difficult for these to compete with modern classification algorithms in performance and even in feature extraction. In this work, we propose a novel approach explicitly designed to address a number of subtle yet important issues which have stymied earlier DML algorithms. It maintains an explicit model of the distributions of the different classes in representation space. It then employs this knowledge to adaptively assess similarity, and achieve local discrimination by penalizing class distribution overlap. We demonstrate the effectiveness of this idea on several tasks. Our approach achieves state-of-the-art classification results on a number of fine-grained visual recognition datasets, surpassing the standard softmax classifier and outperforming triplet loss by a relative margin of 30-40%. In terms of computational performance, it alleviates training inefficiencies in the traditional triplet loss, reaching the same error in 5-30 times fewer iterations. Beyond classification, we further validate the saliency of the learnt representations via their attribute concentration and hierarchy recovery properties, achieving 10-25% relative gains on the softmax classifier and 25-50% on triplet loss in these tasks.
With the widespread availability of cellphones and cameras that have GPS capabilities, it is common for images being uploaded to the Internet today to have GPS coordinates associated with them. In addition to research that tries to predict GPS coordinates from visual features, this also opens up the door to problems that are conditioned on the availability of GPS coordinates. In this work, we tackle the problem of performing image classification with location context, in which we are given the GPS coordinates for images in both the train and test phases. We explore different ways of encoding and extracting features from the GPS coordinates, and show how to naturally incorporate these features into a Convolutional Neural Network (CNN), the current state-of-the-art for most image classification and recognition problems. We also show how it is possible to simultaneously learn the optimal pooling radii for a subset of our features within the CNN framework. To evaluate our model and to help promote research in this area, we identify a set of location-sensitive concepts and annotate a subset of the Yahoo Flickr Creative Commons 100M dataset that has GPS coordinates with these concepts, which we make publicly available. By leveraging location context, we are able to achieve almost a 7% gain in mean average precision.
We propose a simple, yet effective approach for spatiotemporal feature learning using deep 3-dimensional convolutional networks (3D ConvNets) trained on a large scale supervised video dataset. Our findings are three-fold: 1) 3D ConvNets are more suitable for spatiotemporal feature learning compared to 2D ConvNets; 2) A homogeneous architecture with small 3x3x3 convolution kernels in all layers is among the best performing architectures for 3D ConvNets; and 3) Our learned features, namely C3D (Convolutional 3D), with a simple linear classifier outperform state-of-the-art methods on 4 different benchmarks and are comparable with current best methods on the other 2 benchmarks. In addition, the features are compact: achieving 52.8% accuracy on UCF101 dataset with only 10 dimensions and also very efficient to compute due to the fast inference of ConvNets. Finally, they are conceptually very simple and easy to train and use.
We explore the task of recognizing peoples' identities in photo albums in an unconstrained setting. To facilitate this, we introduce the new People In Photo Albums (PIPA) dataset, consisting of over 60000 instances of over 2000 individuals collected from public Flickr photo albums. With only about half of the person images containing a frontal face, the recognition task is very challenging due to the large variations in pose, clothing, camera viewpoint, image resolution and illumination. We propose the Pose Invariant PErson Recognition (PIPER) method, which accumulates the cues of poselet-level person recognizers trained by deep convolutional networks to discount for the pose variations, combined with a face recognizer and a global recognizer. Experiments on three different settings confirm that in our unconstrained setup PIPER significantly improves on the performance of DeepFace, which is one of the best face recognizers as measured on the LFW dataset.
This paper addresses the problem of clustering a very large number of photos (i.e. hundreds of millions a day) in a stream into millions of clusters. This is particularly important as the popularity of photo sharing websites, such as Facebook, Google, and Instagram. Given large number of photos available online, how to efficiently organize them is an open problem. To address this problem, we propose to cluster the binary hash codes of a large number of photos into binary cluster centers. We present a fast binary k-means algorithm that works directly on the similarity-preserving hashes of images and clusters them into binary centers on which we can build hash indexes to speedup computation. The proposed method is capable of clustering millions of photos on a single machine in a few minutes. We show that this approach is usually several magnitude faster than standard k-means and produces comparable clustering accuracy. In addition, we propose an online clustering method based on binary k-means that is capable of clustering large photo stream on a single machine, and show applications to spam detection and trending photo discovery.
The availability of large labeled datasets has allowed Convolutional Network models to achieve impressive recognition results. However, in many settings manual annotation of the data is impractical; instead our data has noisy labels, i.e. there is some freely available label for each image which may or may not be accurate. In this paper, we explore the performance of discriminatively-trained Convnets when trained on such noisy data. We introduce an extra noise layer into the network which adapts the network outputs to match the noisy label distribution. The parameters of this noise layer can be estimated as part of the training process and involve simple modifications to current training infrastructures for deep networks. We demonstrate the approaches on several datasets, including large scale experiments on the ImageNet classification benchmark.
We present a new dataset with the goal of advancing the state-of-the-art in object recognition by placing the question of object recognition in the context of the broader question of scene understanding. This is achieved by gathering images of complex everyday scenes containing common objects in their natural context. Objects are labeled using per-instance segmentations to aid in precise object localization. Our dataset contains photos of 91 objects types that would be easily recognizable by a 4 year old. With a total of 2.5 million labeled instances in 328k images, the creation of our dataset drew upon extensive crowd worker involvement via novel user interfaces for category detection, instance spotting and instance segmentation. We present a detailed statistical analysis of the dataset in comparison to PASCAL, ImageNet, and SUN. Finally, we provide baseline performance analysis for bounding box and segmentation detection results using a Deformable Parts Model.
We propose a method for inferring human attributes (such as gender, hair style, clothes style, expression, action) from images of people under large variation of viewpoint, pose, appearance, articulation and occlusion. Convolutional Neural Nets (CNN) have been shown to perform very well on large scale object recognition problems. In the context of attribute classification, however, the signal is often subtle and it may cover only a small part of the image, while the image is dominated by the effects of pose and viewpoint. Discounting for pose variation would require training on very large labeled datasets which are not presently available. Part-based models, such as poselets and DPM have been shown to perform well for this problem but they are limited by flat low-level features. We propose a new method which combines part-based models and deep learning by training pose-normalized CNNs. We show substantial improvement vs. state-of-the-art methods on challenging attribute classification tasks in unconstrained settings. Experiments confirm that our method outperforms both the best part-based methods on this problem and conventional CNNs trained on the full bounding box of the person.
Poselets have been used in a variety of computer vision tasks, such as detection, segmentation, action classification, pose estimation and action recognition, often achieving state-of-the-art performance. Poselet evaluation, however, is computationally intensive as it involves running thousands of scanning window classifiers. We present an algorithm for training a hierarchical cascade of part-based detectors and apply it to speed up poselet evaluation. Our cascade hierarchy leverages common components shared across poselets. We generate a family of cascade hierarchies, including trees that grow logarithmically on the number of poselet classifiers. Our algorithm, under some reasonable assumptions, finds the optimal tree structure that maximizes speed for a given target detection rate. We test our system on the PASCAL dataset and show an order of magnitude speedup at less than 1% loss in AP.
We address the problem of detecting people in natural scenes using a part approach based on poselets. We propose a bootstrapping method that allows us to collect millions of weakly labeled examples for each poselet type. We use these examples to train a Convolutional Neural Net to discriminate different poselet types and separate them from the background class. We then use the trained CNN as a way to represent poselet patches with a Pose Discriminative Feature (PDF) vector -- a compact 256-dimensional feature vector that is effective at discriminating pose from appearance. We train the poselet model on top of PDF features and combine them with object-level CNNs for detection and bounding box prediction. The resulting model leads to state-of-the-art performance for human detection on the PASCAL datasets.
We propose a novel approach for human pose estimation in real-world cluttered scenes, and focus on the challenging problem of predicting the pose of both arms for each person in the image. For this purpose, we build on the notion of poselets and train highly discriminative classifiers to differentiate among arm configurations, which we call armlets. We propose a rich representation which, in addition to standard HOG features, integrates the information of strong contours, skin color and contextual cues in a principled manner. Unlike existing methods, we evaluate our approach on a large subset of images from the PASCAL VOC detection dataset, where critical visual phenomena, such as occlusion, truncation, multiple instances and clutter are the norm. Our approach outperforms Yang and Ramanan, the state-of-the-art technique, with an improvement from 29.0% to 37.5% PCP accuracy on the arm keypoint prediction task, on this new pose estimation dataset.
We address the problem of interactive facial feature localization from a single image. Our goal is to obtain an accurate segmentation of facial features on high-resolution images under a variety of pose, expression, and lighting conditions. Although there has been significant work in facial feature localization, we are addressing a new application area, namely to facilitate intelligent high-quality editing of portraits, that brings requirements not met by existing methods. We propose an improvement to the Active Shape Model that allows for greater independence among the facial components and improves on the appearance fitting step by introducing a Viterbi optimization process that operates along the facial contours. Despite the improvements, we do not expect perfect results in all cases. We therefore introduce an interaction model whereby a user can efficiently guide the algorithm towards a precise solution. We introduce the Helen Facial Feature Dataset consisting of annotated portrait images gathered from Flickr that are more diverse and challenging than currently existing datasets. We present experiments that compare our automatic method to published results, and also a quantitative evaluation of the effectiveness of our interactive method.
We address the problem of segmenting and recognizing objects in real world images, focusing on challenging articulated categories such as humans and other animals. For this purpose, we propose a novel design for region-based object detectors that integrates efficiently top-down information from scanning-windows part models and global appearance cues. Our detectors produce class-specific scores for bottom-up regions, and then aggregate the votes of multiple overlapping candidates through pixel classification. We evaluate our approach on the PASCAL segmentation challenge, and report competitive performance with respect to current leading techniques. On VOC2010, our method obtains the best results in 6/20 categories and the highest performance on articulated objects.
We address the problem of editing facial expression in video, such as exaggerating, attenuating or replacing the expression with a different one in some parts of the video. To achieve this we develop a tensor-based 3D face geometry reconstruction method, which fits a 3D model for each video frame, with the constraint that all models have the same identity and requiring temporal continuity of pose and expression. With the identity constraint, the differences between the underlying 3D shapes capture only changes in expression and pose. We show that various expression editing tasks in video can be achieved by combining face reordering with face warping, where the warp is induced by projecting differences in 3D face shapes into the image plane. Analogously, we show how the identity can be manipulated while fixing expression and pose. Experimental results show that our method can effectively edit expressions and identity in video in a temporally-coherent way with high fidelity.
The explosive growth in image sharing via social networks has produced exciting opportunities for the computer vision community in areas including face, text, product and scene recognition. In this work we turn our attention to group photos of people and ask the question: what can we determine about the social subculture or urban tribe to which these people belong? To this end, we propose a framework employing low- and mid-level features to capture the visual attributes distinctive to a variety of urban tribes. We proceed in a semi-supervised manner, employing a metric that allows us to extrapolate from a small number of pairwise image similarities to induce a set of groups that visually correspond to familiar urban tribes such as biker, hipster or goth. Automatic recognition of such information in group photos offers the potential to improve recommendation services, context sensitive advertising and other social analysis applications. We present promising preliminary experimental results that demonstrate our ability to categorize group photos in a socially meaningful manner
We address the problem of editing facial expression in video, such as exaggerating, attenuating or replacing the expression with a different one in some parts of the video. To achieve this we develop a tensor-based 3D face geometry reconstruction method, which fits a 3D model for each video frame, with the constraint that all models have the same identity and requiring temporal continuity of pose and expression. With the identity constraint, the differences between the underlying 3D shapes capture only changes in expression and pose. We show that various expression editing tasks in video can be achieved by combining face reordering with face warping, where the warp is induced by projecting differences in 3D face shapes into the image plane. Analogously, we show how the identity can be manipulated while fixing expression and pose. Experimental results show that our method can effectively edit expressions and identity in video in a temporally-coherent way with high fidelity.
We propose a method for recognizing attributes, such as the gender, hair style and types of clothes of people under large variation in viewpoint, pose, articulation and occlusion typical of personal photo album images. Robust attribute classifiers under such conditions must be invariant to pose, but inferring the pose in itself is a challenging problem. We use a part-based approach based on poselets. Our parts implicitly decompose the aspect (the pose and viewpoint). We train attribute classifiers for each such aspect and we combine them together in a discriminative model. We propose a new dataset of 8000 people with annotated attributes. Our method performs very well on this dataset, significantly outperforming a baseline built on the spatial pyramid match kernel method. On gender recognition we outperform a commercial face recognition system.
We study the challenging problem of localizing and classifying category-specific object contours in real world images. For this purpose, we present a simple yet effective method for combining generic object detectors with bottomup contours to identify object contours. We also provide a principled way of combining information from different part detectors and across categories. In order to study the problem and evaluate quantitatively our approach, we present a dataset of semantic exterior boundaries on more than 20, 000 object instances belonging to 20 categories, using the images from the VOC2011 PASCAL challenge
Video tutorials provide a convenient means for novices to learn new software applications. Unfortunately, staying in sync with a video while trying to use the target application at the same time requires users to repeatedly switch from the application to the video to pause or scrub backwards to replay missed steps. We present Pause-and-Play, a system that helps users work along with existing video tutorials. Pauseand-Play detects important events in the video and links them with corresponding events in the target application as the user tries to replicate the depicted prodedure. This linking allows our system to automatically pause and play the video to stay in sync with the user. Pause-and-Play also supports convenient video navigation controls that are accessible from within the target application and allow the user to easily replay portions of the video without switching focus out of the application. Finally, since our system uses computer vision to detect events in existing videos and leverages application scripting APIs to obtain real time usage traces, our approach is largely independent of the specific target application and does not require access or modifications to application source code. We have implemented Pause-and-Play for two target applications, Google SketchUp and Adobe Photoshop, and we report on a user study that shows our system improves the user experience of working with video tutorials.
We address the problem of correcting an undesirable expression on a face photo by transferring local facial components, such as a smiling mouth, from another face photo of the same person which has the desired expression. Direct copying and blending using existing compositing tools results in semantically unnatural composites, since expression is a global effect and the local component in one expression is often incompatible with the shape and other components of the face in another expression. To solve this problem we present Expression Flow, a 2D flow field which can warp the target face globally in a natural way, so that the warped face is compatible with the new facial component to be copied over. To do this, starting with the two input face photos, we jointly construct a pair of 3D face shapes with the same identity but different expressions. The expression flow is computed by projecting the difference between the two 3D shapes back to 2D. It describes how to warp the target face photo to match the expression of the reference photo. User studies suggest that our system is able to generate face composites with much higher fidelity than existing methods.
We present a distributed representation of pose and appearance of people called the “poselet activation vector”. First we show that this representation can be used to estimate the pose of people defined by the 3D orientations of the head and torso in the challenging PASCAL VOC 2010 person detection dataset. Our method is robust to clutter, aspect and viewpoint variation and works even when body parts like faces and limbs are occluded or hard to localize. We combine this representation with other sources of information like interaction with objects and other people in the image and use it for action recognition. We report competitive results on the PASCAL VOC 2010 static image action classification challenge
In this paper, we propose techniques to make use of two complementary bottom-up features, image edges and texture patches, to guide top-down object segmentation towards higher precision. We build upon the part-based poselet detector, which can predict masks for numerous parts of an object. For this purpose we extend poselets to 19 other categories apart from person. We non-rigidly align these part detections to potential object contours in the image, both to increase the precision of the predicted object mask and to sort out false positives. We spatially aggregate object information via a variational smoothing technique while ensuring that object regions do not overlap. Finally, we propose to refine the segmentation based on self-similarity de- fined on small image patches. We obtain competitive results on the challenging Pascal VOC benchmark. On four classes we achieve the best numbers to-date.
We address the classic problems of detection and segmentation using a part based detector that operates on a novel part, which we refer to as a poselet. Poselets are tightly clustered in both appearance space (and thus are easy to detect) as well as in configuration space (and thus are helpful for localization and segmentation). We demonstrate poselets are effective for detection, pose extraction, segmentation, action/pose estimation and attribute classification. Poselet construction requires extra annotations beyond the object bounds. To train poselets we have created H3D (Humans in 3D) - a dataset of 1200+ person annotations. The annotations include the joints, the extracted 3D pose, keypoint visibility and region labels. We have also annotated the people in the training and validation sets of PASCAL VOC 2009. Our poselet classifier achieves state-of-the-art results for the person category on PASCAL VOC 2007, 2008, 2009 and 2010 as well as on our dataset, H3D.
Bourdev and Malik (ICCV 09) introduced a new notion of parts, poselets, constructed to be tightly clustered both in the configuration space of keypoints, as well as in the appearance space of image patches. In this paper we develop a new algorithm for detecting people using poselets. Unlike that work which used 3D annotations of keypoints, we use only 2D annotations which are much easier for naive human annotators. The main algorithmic contribution is in how we use the pattern of poselet activations. Individual poselet activations are noisy, but considering the spatial context of each can provide vital disambiguating information, just as object detection can be improved by considering the detection scores of nearby objects in the scene. This can be done by training a two-layer feed-forward network with weights set using a max margin technique. The refined poselet activations are then clustered into mutually consistent hypotheses where consistency is based on empirically determined spatial keypoint distributions. Finally, bounding boxes are predicted for each person hypothesis and shape masks are aligned to edges in the image to provide a segmentation. To the best of our knowledge, the resulting system is the current best performer on the task of people detection and segmentation with an average precision of 47.8% and 40.5% respectively on PASCAL VOC 2009.
We address the classic problems of detection, segmentation and pose estimation of people in images with a novel definition of a part, a poselet. We postulate two criteria (1) It should be easy to find a poselet given an input image (2) it should be easy to localize the 3D configuration of the person conditioned on the detection of a poselet. To permit this we have built a new dataset, H3D, of annotations of humans in 2D photographs with 3D joint information, inferred using anthropometric constraints. This enables us to implement a data-driven search procedure for finding poselets that are tightly clustered in both 3D joint configuration space as well as 2D image appearance. The algorithm discovers poselets that correspond to frontal and profile faces, pedestrians, head and shoulder views, among others. Each poselet provides examples for training a linear SVM classifier which can then be run over the image in a multiscale scanning mode. The outputs of these poselet detectors can be thought of as an intermediate layer of nodes, on top of which one can run a second layer of classification or regression. We show how this permits detection and localization of torsos or keypoints such as left shoulder, nose, etc. Experimental results show that we obtain state of the art performance on people detection in the PASCAL VOC 2007 challenge, among other datasets. We are making publicly available both the H3D dataset as well as the poselet parameters for use by other researchers.
The Generic Image Library (GIL) is a C++ image library sponsored by Adobe Systems, Inc. and developed by Lubomir Bourdev and Hailin Jin. It is an open-source library, planned for inclusion in Boost 1.35.0. GIL is also a part of the Adobe Source Libraries. It is used in several Adobe projects, including some new features in Photoshop CS4
Generic programming with C++ templates results in efficient but inflexible code: efficient, because the exact types of inputs to generic functions are known at compile time; inflexible because they must be known at compile time. We show how to achieve run-time polymorphism without compromising performance by instantiating the generic algorithm with a comprehensive set of possible parameter types, and choosing the appropriate instantiation at run time. Applying this approach naïvely can result in excessive template bloat: a large number of template instantiations, many of which are identical at the assembly level. We show practical examples of this approach quickly approaching the limits of the compiler. Consequently, we combine this method of run-time polymorphism for generic programming, with a strategy for reducing the number of necessary template instantiations. We report on using our approach in GIL, Adobe’s open source Generic Image Library. We observed a notable reduction, up to 70% at times, in executable sizes of our test programs. This was the case even with compilers that perform aggressive template hoisting at the compiler level, due to significantly smaller dispatching code. The framework draws from both the generic and generative programming paradigms, using static metaprogramming to fine tune the compilation of a generic library. Our test bed, GIL, is deployed in a real world industrial setting, where code size is often an important factor.
We describe a method for training object detectors using a generalization of the cascade architecture, which results in a detection rate and speed comparable to that of the best published detectors while allowing for easier training and a detector with fewer features. In addition, the method allows for quickly calibrating the detector for a target detection rate, false positive rate or speed. One important advantage of our method is that it enables systematic exploration of the ROC Surface, which characterizes the trade-off between accuracy and speed for a given classifier.
Artists and illustrators can evoke the complexity of fur or vegetation with relatively few well-placed strokes. We present an algorithm that uses strokes to render 3D computer graphics scenes in a stylized manner suggesting the complexity of the scene without representing it explicitly. The basic algorithm is customizable to produce a range of effects including fur, grass and trees, as we demonstrate in this paper and accompanying video. The algorithm is implemented within a broader framework that supports procedural stroke-based textures on polyhedral models. It renders moderately complex scenes at multiple frames per second on current graphics workstations, and provides some interframe coherence.
We describe a method for rendering a silhouette of an object in a frame-to-frame coherent way. The input to the system each frame is a set of silhouette pixels in a rendering of the object and their corresponding silhouette edges in a polygonal model (mesh) of the object. The output is a set of silhouette strokes.
Nonphotorealistic rendering (NPR) can help make comprehensible but simple pictures of complicated objects by employing an economy of line. But current nonphotorealistic rendering is primarily a batch process. This paper presents a real-time nonphotorealistic renderer that deliberately trades accuracy and detail for speed. Our renderer uses a method for determining visible lines and surfaces which is a modification of Appel’s hidden-line algorithm, with improvements which are based on the topology of singular maps of a surface into the plane. The method we describe for determining visibility has the potential to be used in any NPR system that requires a description of visible lines or surfaces in the scene. The major contribution of this paper is thus to describe a tool which can significantly improve the performance of these systems. We demonstrate the system with several nonphotorealistic rendering styles, all of which operate on complex models at interactive frame rates.
Some of the projects I have developed have been mentioned in the media
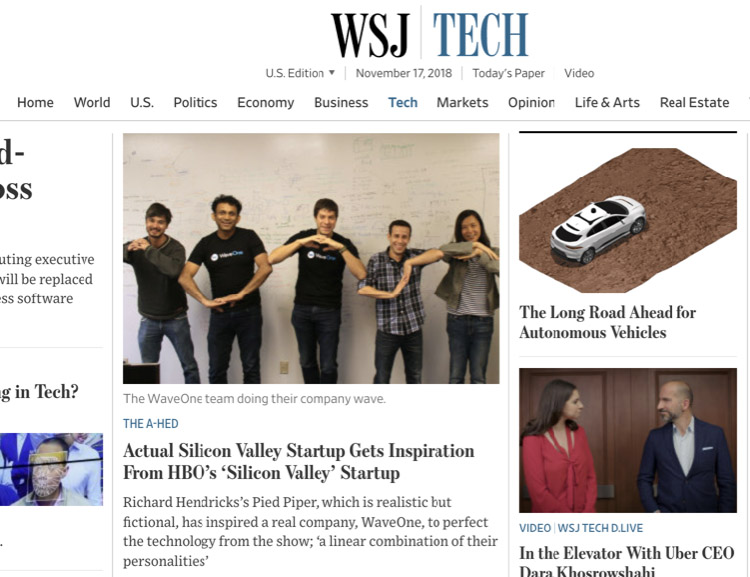
I am humbled to see the company I co-founded featured on the front page of the Wall Street Journal. According Rolfe Winkler, the journalist, we were the first pre-Series A startup to ever make it on the front page. While we are proud with our technology, being the first to outperform the video standards in the low-latency mode, what helped with this article is our uncanny resemblance to Pied Piper, the video compression startup in the HBO series Silicon Valley. Funny story: The article featured a photo in front of our white board which contained, at the time, confidential formulas. We only realized our mistake once we saw the photo on the WSJ website!

I was featured in the book by Cade Metz, a New York Times technology correspondent, on my role in the early days of what became Facebook AI Research. On pages 124-127 the book describes how I used out-of-the-box tactics and, with the help of Mark Zuckerberg (CEO) and Mike Schroepfer (CTO) I was able to hire a key Google researcher Marc-Aurelio Ranzato. Once he joined Facebook, he was instrumental in attracting his former advisor Prof. Yann LeCun to join and lead FAIR, and also Prof. Rob Fergus. On page 323 the book identifies the six of us as the key people behind the formation of Facebook AI Research.

Here is a TechCrunch article about WaveOne, the company I co-founded, in association with our fundrasing round.
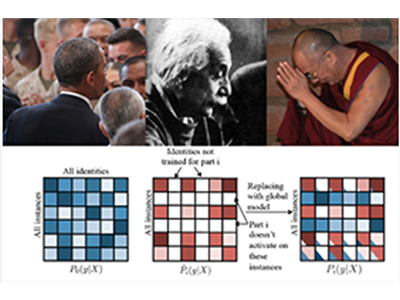
My former intern Ning Zhang and I, together with colleagues from Facebook AI Research, published a CVPR poster about recognizing people even if their face is not visible. It went largely unnoticed in the vision community until it was suddenly picked by the press, with dozens of articles about it - by Wired, Time, Wall Street Journal, The Hacker News, Fortune, Another one by WSJ, New Scientist, ZDNet, Business Insider, Huffington Post, Yahoo, Daily Mail, USA Today and many other ones. They even made a Jimmy Kimmel skit! While I can't help feeling flattered by the press attention and think of PIPER as is a neat project and the first of its kind to recognize people from any viewpoint without the presence of a face, I feel this work is being overhyped, certainly not worth being called "technological breakthrough". A lot of the articles expressed privacy concerns (which are unwarranted -- this is a research-only project with no plans to deploy to production).

Here is a Wall Street Journal article written in 2008 about young researchers and the age span of inventors across different companies. It mentions me in the section about Adobe. (At that time I was considered "young"!)
The best way to reach me is to send an email to myfirstname.mylastname@gmail.com